This post is part of a series on creating and using local printed maps. Start here.
Hitting print on a USGS 7.5 minute map in Chrome brings up no good options for producing a hard copy. Sure, you can 'fit to page', but doing so results in a squished map.

The USGS, however, offers an elegant solution in their tutorial: Lesson 8b - Printing US Topos. If you open the PDF in Adobe Reader and hit print, you can choose the 'Poster' option. Doing so will result in the document being printed as a series of tiles, one per page, that as the name suggests could be taped together to form one large poster.

This is a clever way to print out the map and have it remain at its intended size. This is especially important because it results in a map that can be used with standard UTM map measuring tools. For example, the ones provided over at MapTools.com. Here's a page from a poster printed map with a Map Tools grid overlay:
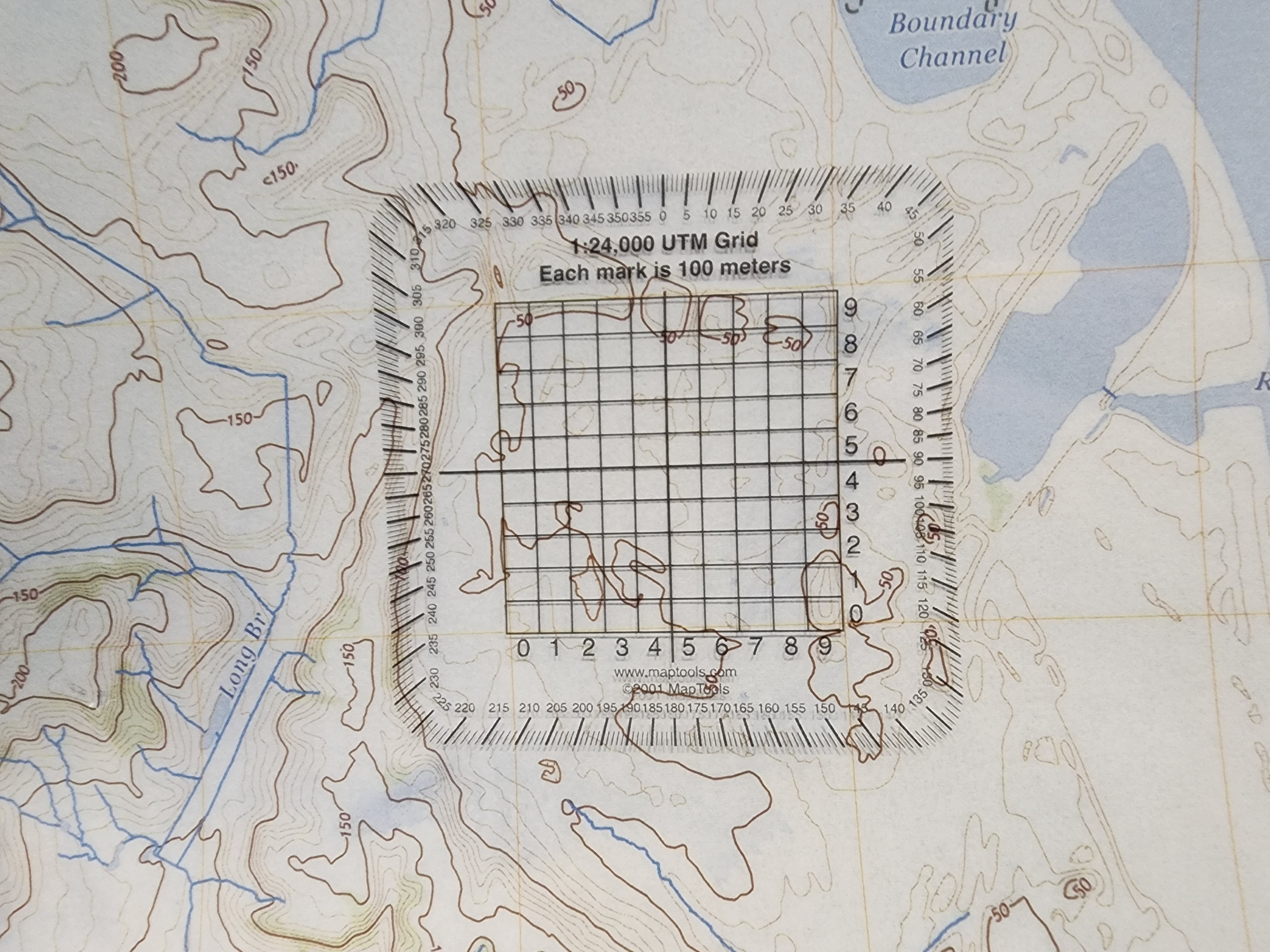
This grid vastly simplifies the process of pinpointing GPS locations on a physical map. Check this tutorial out to see what I mean.
One optional step is to poster-print the map to a PDF file. This results in a 9 page PDF file that can be opened and printed accurately using any PDF reader. This is handy if you're only interested in one tile or page of the map. For example, to experiment with navigating and annotating around my local neighborhood, I may print 5 copies of page 3 of this posterized PDF.


If you're interested in just a part of the map, the USGS Tutorial suggests another option: take advantage of Adobe Reader's print 'Current View.' This will cleanly print the area you've zoomed into on the map:


After finding and preparing a topo-centric view of my neighborhood, I was able to print the map using the poster approach described above.

Now it's now time to get my 'Lewis and Clark' on and go exploring!
































































